Start a streaming session
Get real-time predictions using the streaming endpoint
Behavioral Signals API offers real-time emotion & behavior recognition and deepfake detection. In this guide we'll provide a starting point for using the streaming endpoint. For more information visit the Streaming API section of the documentation.
🖥️ Start a stream - using the UI
The UI provides a simple and way to try out the streaming endpoint. For production use or automation, we recommend using the official SDK or creating a gRPC client using the .proto file.
From the Projects page, select your Project and click on Stream From Mic
This will open a popup that allows streaming audio from your microphone to the API (You'll need to allow the use of microphone when prompted by the browser). Once you click on Start Streaming you can start talking and the results will appear and refresh in real time.
To stop recording, click on Stop & Close or Cancel
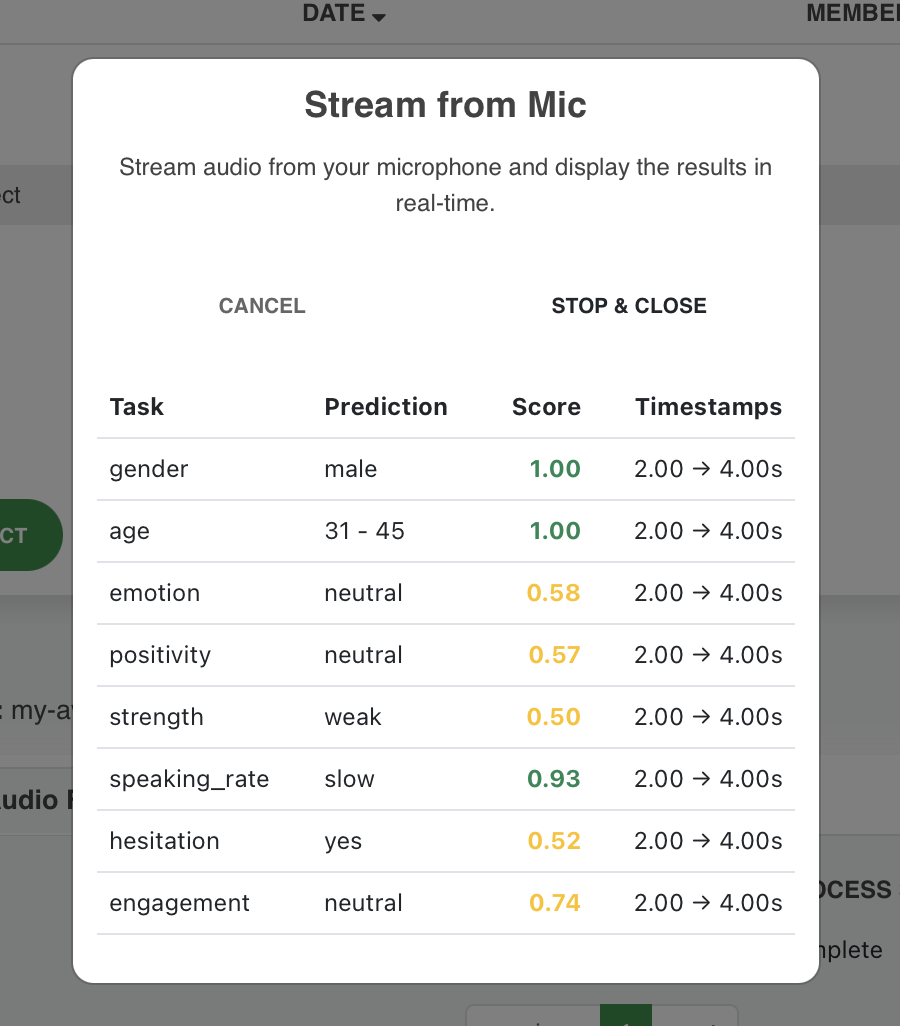
The table shows a list of tasks, which correspond to the speech attributes that our API detects. The final prediction for each task is displayed in the Prediction column. The Score column indicates the confidence of the prediction (posterior probability of the dominant class).
🐍 Start a stream - using the Python SDK
The recommended way of using the streaming capability of the API is from the official Python SDK.
After you have installed the dependency through PyPI, you can initiate a new stream like this (e.g. from a file) :
from behavioralsignals import Client, StreamingOptions
from behavioralsignals.utils import make_audio_stream
cid = "<your-cid>"
token = "<your-api-token>"
file_path = "/path/to/audio.wav"
client = Client(cid, token)
audio_stream, sample_rate = make_audio_stream(file_path, chunk_size=250)
options = StreamingOptions(sample_rate=sample_rate, encoding="LINEAR_PCM")
for result in client.behavioral.stream_audio(audio_stream=audio_stream, options=options):
print(result)- The
make_audio_streamis a utility method that read an audio file and transforms it to chunks of fixed size. - Alternatively, you can use any
Iterator[bytes]input toclient.behavioral.stream_audio - The
StreamingOptionsdefine the sample rate and encoding of the audio (onlyLinear PCMsupported at the moment) - The method yields objects of type
StreamingResultResponse, defined here